Aproveitamento de dados industriais: Transformando dados fragmentados em vantagem competitiva

A quantidade de dados coletados de processos industriais está aumentando em uma velocidade acelerada. Os modernos sistemas de computador permitem que os dados sejam armazenados por longos períodos de tempo e em uma taxa de amostragem muito mais rápida do que nunca. Isso levanta uma questão importante: O que fazer com todos esses dados?
As empresas de “B-to-C” têm coletado e analisado com sucesso dados grandes e complexos de transações de clientes há vários anos. Essa “abordagem de big data” tem como objetivo dar a elas uma vantagem competitiva sobre seus rivais. As empresas industriais de “B-to-B” ainda não estão no mesmo nível, mas a concorrência cada vez maior as obriga a ajustar seus processos de fabricação. As empresas são forçadas a produzir melhor qualidade em quantidades maiores e, ao mesmo tempo, reduzir o consumo de energia e os custos de matéria-prima.
Esses problemas podem ser resolvidos permitindo que os funcionários aprimorem os processos de fabricação com base em dados medidos de séries temporais.
Ao aplicar métodos e ferramentas eficientes de tratamento de dados, as empresas industriais podem descobrir o potencial inexplorado em seus dados existentes, o que leva a diagnósticos de processos aprimorados e a uma vantagem competitiva.
Desafios da utilização de dados fragmentados
Durante a última década, as informações digitais, o controle de processos e os sistemas de execução de negócios tornaram-se aplicativos padrão no setor de papel e celulose. Ao mesmo tempo, as quantidades de dados coletados e salvos aumentaram significativamente, e essa tendência continuará no futuro.
Os sistemas usados nas fábricas geralmente se concentram em uma área de processo limitada (por exemplo, manuseio de matéria-prima, preparação de estoque, seção de bobinas) ou em um tipo de dados limitado (por exemplo, dados da malha de controle, dados de processo, dados de qualidade e dados de custo).
Atualmente, grandes quantidades de dados são coletadas, mas apenas uma pequena parte é utilizada. Uma planta de produção ou uma empresa inteira obteria grandes benefícios se todos esses dados fossem combinados de forma integrada, e os funcionários teriam uma visão total do processo.
Combinação de conhecimento especializado com gerenciamento eficiente de dados
A massa de dados coletados contém muito potencial de melhoria de processos e negócios não utilizados. Para aproveitar esse potencial, é necessário um sistema eficiente de gerenciamento de dados.
Um sistema eficiente de gerenciamento de dados permite a combinação de todas as fontes de dados em um único sistema. Uma interface de usuário amigável ajuda o usuário a obter informações e conhecimentos úteis a partir dessa enorme quantidade de dados. O usuário não precisa gastar muito tempo inserindo dados no sistema de gerenciamento de dados; em vez disso, ele deve se concentrar apenas na solução do problema, no aumento da eficiência ou na melhoria da qualidade do produto final.
As relações entre os fenômenos do processo são muito complicadas, e várias medições afetam umas às outras. Portanto, muitas vezes é necessário combinar as medições originais em medições novas e mais úteis, por exemplo, para calcular o fluxo de sólidos secos com base nas medições originais de fluxo e consistência. Para permitir esse tipo de modificação livre de dados, deve haver uma maneira fácil de adicionar os próprios cálculos ao sistema de manuseio de dados.
Processo de análise de dados: Um fluxo de trabalho orientado pelo sistema ou um fluxo mental orientado pelo ser humano?
A análise do processo pode ser iniciada quando todos os dados relevantes estiverem disponíveis no sistema de tratamento de dados. A Figura 1 ilustra a análise simplificada dos dados do processo ou o fluxo de trabalho do ciclo de solução de problemas.
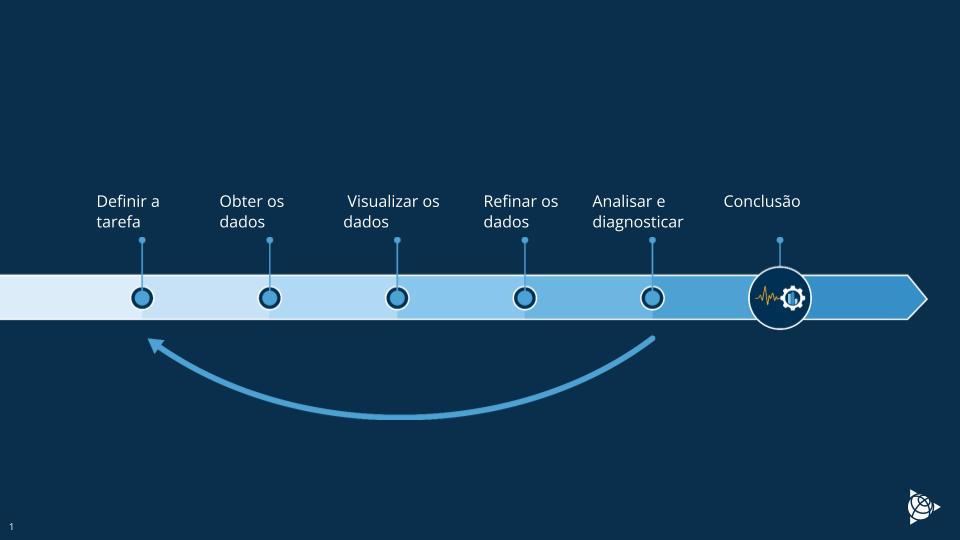
A primeira etapa é definir o objetivo: o que precisamos descobrir?
A próxima etapa é criar um conjunto funcional de medições. Nesse ponto, é importante combinar dados de diferentes fontes em um único sistema. A conexão de dados deve ser on-line para evitar importações de dados trabalhosas e lentas para o sistema de análise. Os dados também devem estar próximos do tempo real para permitir reações rápidas às situações que surgirem.
Os dados do processo sempre contêm alguns valores ruins, por exemplo, grandes valores discrepantes, valores errôneos e valores de dados de períodos de parada de fábrica. Esse tipo de dados ruins afeta muito os resultados da análise e, portanto, esses valores devem ser removidos antes da análise. Para realizar esse tipo de limpeza de dados de forma eficiente, a ferramenta deve apoiar o conhecimento do processo do usuário. Um funcionário experiente com conhecimento do processo é o melhor em julgar quais valores são irrelevantes e, então, esses valores devem poder ser removidos facilmente do conjunto de dados.
Quando os dados são limpos, o usuário pode realizar a análise do processo, por exemplo, estatísticas e cálculos de correlação. Nessa etapa, é comum que o usuário já encontre algumas informações úteis nos dados, mas quando há muitas medições, isso pode ser trabalhoso. O poder computacional pode ser usado para tornar essa etapa muito mais eficiente. Um computador pode verificar rapidamente várias medições de processo e qualidade para determinar qual delas se correlaciona melhor com a meta definida. O sistema deve ser capaz de classificar as medições e fornecer uma lista de medições candidatas que parecem afetar mais a medição da meta. Nessa etapa, os dados são transformados em informações.
É importante lembrar que o usuário deve ter um bom conhecimento do processo para obter resultados úteis do estudo e tirar conclusões confiáveis. Nesta etapa, as informações são transformadas em novos conhecimentos. Se necessário, o usuário pode redefinir a tarefa e iniciar o ciclo novamente.
Na vida real, um fluxo de trabalho de análise de dados bom e eficiente não é linear e simples como descrito acima; ele se parece mais com uma bola de espaguete.
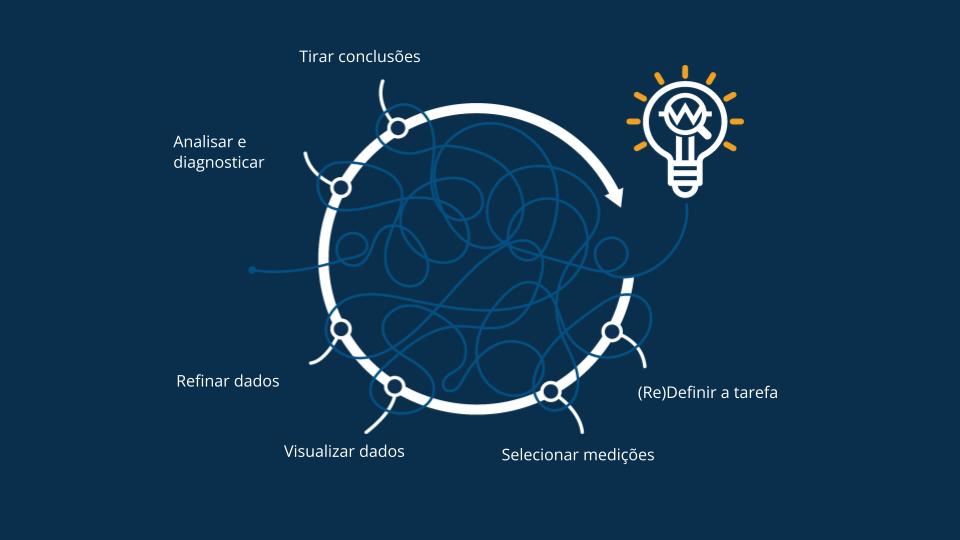
Novas informações e percepções surgem inevitavelmente quando os dados são processados por meio de métodos criativos de limpeza, refinamento, cálculos e análise. Isso orienta a análise de dados. Muitas vezes, essas novas percepções resultam na redefinição da pergunta original.
Em um fluxo de trabalho de análise de dados eficiente, novas percepções são criadas em todas as etapas. Os sistemas de análise de dados devem dar suporte a esse estilo de trabalho ágil e criativo. Os usuários devem ser capazes de modificar o conjunto de dados, tentar diferentes cenários de limpeza de dados e experimentar diferentes métodos de análise de forma ágil.
Melhor uso dos dados para enfrentar os desafios de produtividade e sustentabilidade
Embora a quantidade de dados esteja aumentando em uma velocidade acelerada, os recursos nas fábricas estão diminuindo. A concorrência entre empresas é acirrada, e a situação não será mais fácil no futuro. Além de tudo isso, a importância de economizar recursos naturais também está aumentando.
Isso força as empresas a executar processos de forma mais eficiente e sustentável. Uma das maneiras mais econômicas de atingir as metas é utilizar os dados existentes de forma mais eficiente.
Atualmente, a equipe da fábrica precisa lidar com muitas tarefas diferentes simultaneamente. Isso significa que eles não podem dedicar muito tempo ao gerenciamento de dados. É necessária uma ferramenta eficiente e intuitiva para combinar todos os dados relevantes em uma mesma visualização. O usuário com bom conhecimento do processo deve ser capaz de obter respostas do sistema para questões de problemas do processo de forma rápida e fácil.
 Quer saber Mais?
Quer saber Mais?
Nosso Time tem vários especialistas em análises de dados e prontos para ajudar. Leia mais sobre, Wedge para análise de dados industriais.